GraphQL in an Event Sourcing Microservices Architecture
by Devonte Emokpae, Founder / CTO
Abstract
There has been a rise of many new technological advances in the space of application development and none more developer-centric than GraphQL.
GraphQL, open-sourced by Facebook, acts as a replacement for the REST API Architecture. It can be understood as a query language for APIs just in the same way that you have query languages for databases (SQL) or query languages for information retrieval systems (CQL).
You can enable a declarative data fetching paradigm by exposing a single endpoint that responds to queries for what the user requires and ONLY what the user requires.
GraphQL can be simply treated as a middleware layer for the backend and thus does not need changes to an existing system.
Top tip
Optimize Queries with GraphQL Batching: In an event sourcing microservices architecture, efficient data retrieval is paramount. Use GraphQL batching techniques to consolidate multiple queries into a single request. Tools like DataLoader in GraphQL can help minimize database trips, reduce latency, and improve overall performance. By optimizing your GraphQL queries, you'll make the most of your resources and deliver a responsive and cost-efficient application.
What is covered
This document aims to bring some understanding to how GraphQL fits perfectly into any microservices architecture but unlocks even more powers when used with Event Sourcing, CQRS, and SAGAs
You will learn how GraphQL:
- Simplifies API evolution
- Improves system reliability
- Helps ensure a logical system
Methodology
Extensive research has been done on this topic in multiple articles, blog posts, and books. I will be bringing all this together in a cohesive manner that should help when considering the implementation details of a system using GraphQL.
This document will explain multiple approaches possible and describe how a hybrid approach gives us the best flexibility and evolution path with minimal friction to the developers, architects, and company as a whole.
Microservices
It is becoming almost a standardization of backend systems to break down monolithic architecture into microservices. These services give us a small API surface to reason about and compose together to build a highly scalable & reliable system.
The complexity of microservices comes in part from the increased number of integration points that one has to take care of.
Stepping back into a microservice architecture there are multiple design trade-offs that you have to make. The design you choose will depend on the kind of end-to-end service you offer to your users.
One of the most fundamental decisions you will make is the choice of “eventual” vs “strong” consistency.
Advantages
- Highly maintainable and testable
- Loosely coupled
- Independently deployable
- Organized around business capabilities
- Owned by a small team
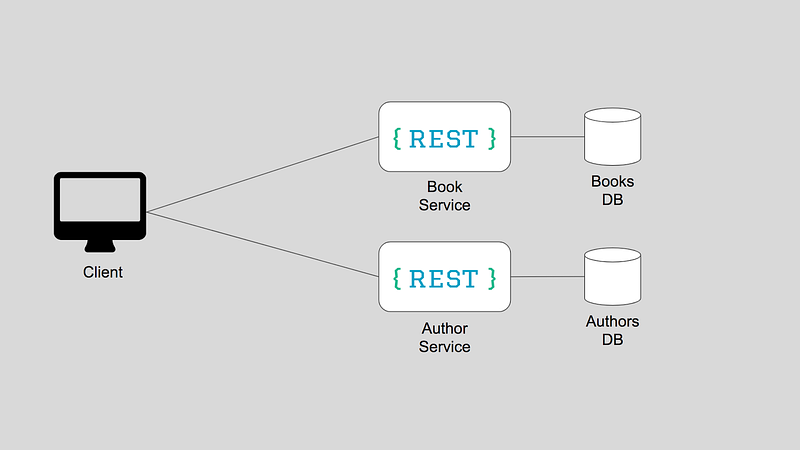
All the benefits of a microservice architecture also pose a challenge for consumers of these APIs. A client needing data from different microservices must make an API call, at times sequentially, to each microservice and aggregate the data itself for consumption in the UI.
Not only do you get a problem of over-fetching and under-fetching with these APIs but what is even worse is that this same logic has to be repeated in each client and thus breaks DRY, a basic principle of software development aimed at reducing repetition of information. This principle states that “Every piece of knowledge or logic must have a single, unambiguous representation within a system”
Disadvantages
- Multiple API class needed to get relevant data
- Having each microservice exposed increases the number of possible attack vectors
- Small changes to APIs need to be versioned and if not handled properly adds brittleness to the client, server, and system as a whole
Why Not REST
When viewed from the client`s perspective there are multiple challenges with REST APIs. GraphQL implementations rely on a single endpoint while with a traditional REST architecture you need explicit documentation to discover all the possible resources.
Advantages
- Web standard
- Easier to cache
- File uploads as a first-class citizen
- Can implement everything GraphQL can with the use of JSON:API spec
- Scales indefinitely
- High performance
- Proven for decades
- Full decoupling of server and client
Disadvantages
- Using multiple endpoints to merge data before displaying it to the user
- Server driven representation of resources
- Over & under fetching
- Slower client product iteration
- True REST APIs are incredibly hard to pull off
- Challenging to keep consistency and governance
- Poor or no tooling for clients
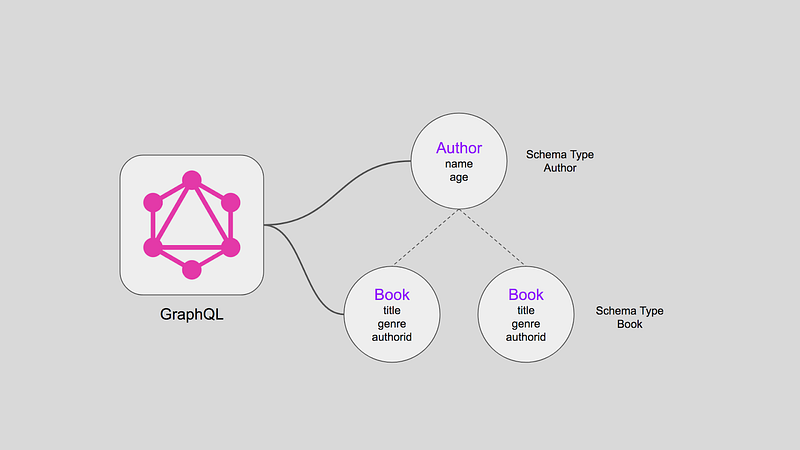
Why GraphQL
GraphQL helps solve a lot of the problems produced by adopting a microservice architecture. You can leverage GraphQL as an “API gateway” due to the fact you interact with multiple microservices that are each dedicated to a single resource type.
You do not need to change your current architecture as you just leverage the power of GraphQL and allow you to create a much simpler architecture while still achieving all of the advantages of a microservices architecture.
What embraces the DRY principle in an API architecture better than GraphQL? It is one and ONLY one endpoint a client ever has to know of and send requests to
Advantages
- API evolution without versioning
- Workable documentation
- Avoids over & under fetching
- A convenient way to aggregate data from multiple sources
- Flexible & performant with parallel execution
- Caching using native object identifiers
- Graceful failure handling and retries
- API as a first-class product
- Dynamic security
- Type system
Disadvantages
- Deceptive JSON-like syntax
- Difficulty to implement rate limiting
- Possible addition of more complexity with the addition of another service
- Caching at the network level
- Handling file uploads
- Circular queries
- Authentication & Authorization
- All queries return a 200 status code even if it contains errors
Why Apollo
GraphQL can be used without a library but a library helps with a lot of the heavy lifting.
Apollo has become synonymous with GraphQL as it is the most full-featured library that supercharges your GraphQL implementation.
Apollo is broken up into multiple parts which put together gives you the most flexibility without compromising on the benefits of GraphQL.
Apollo Client
A tool that helps you use GraphQL in the frontend. It helps with writing queries as part of its components and writing those queries declaratively. It also helps with state management which is needed by big applications.
It Integrates with multiple libraries and frameworks both on the web and mobile.
It also works with any GraphQL server, so does not have to use the Apollo Server if not needed.
Apollo Server
You can use this as your main API and talk directly to the databases(s) or most likely as an API Gateway.
Using the Apollo Server as a gateway, you can aggregate multiple data sources, and the server handles all the different requests before returning to the client.
This limits the number of services that need to understand and speak the GraphQL language.
The API Gateway approach also allows us to swap out if a better way is found to aggregate microservices without needing to affect the APIs themselves.
Apollo Federation
To get the most out of GraphQL it would be best for us to expose a single data graph, providing a unified interface for querying all combinations of backing data sources.
Advantages
- Huge ecosystem
- Company and community support
- Additional libraries
- Built-in features
- Interoperability with other frameworks
- Modern data handling
- State management
However, with an enterprise-scale data graph, it would become monolithic to build that all in one place.
This is where the Apollo Federation comes in. You can break up your graph into much smaller composable services and stitch it all together with Apollo Federation.
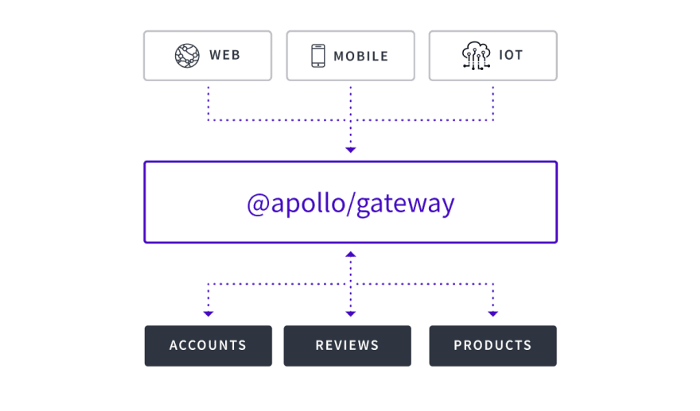
Where It Fits
Mobile Clients
Mobile and GraphQL are made for each other. The ability for the client to drive the amount of and structure of data. The power now goes to the client and while developing should shorten the round-time when some new data is needed.
Admin Panels
Admin panels will need synchronous data and will be able to access this using the same endpoint as all the other clients and thus the capability to get all the data in the same way a non-admin user would (and more).
External (Open) API
While building a system for internal use, you also have the ability to extend that out for external applications (securely). With detailed, auto-generated, Schema documentation that evolves with updates to the system, a robust API can be provided for these external applications.
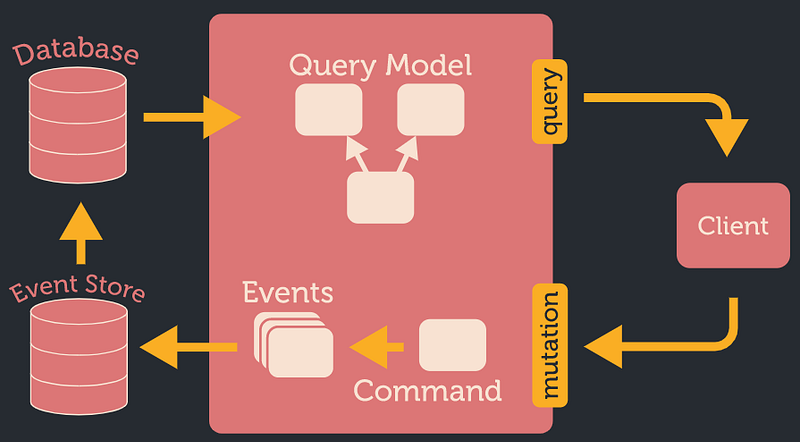
CQRS
The fact that query and mutation are two separate GraphQL types gives us a hint, that a “read” model and a “write” model are separated and don`t necessarily have the same representation.
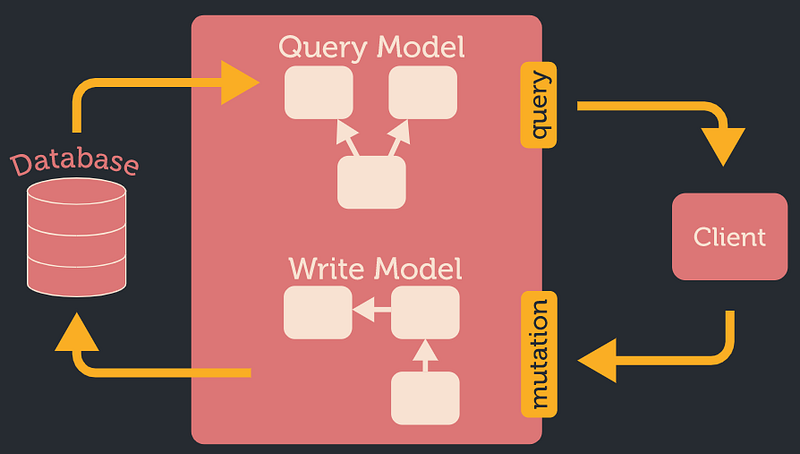
Event Sourcing
There is also another useful pattern that is often used in combination with read-write model separation: event-sourcing. It generally says that a result of “command” is a list of events that can be saved and then used to create a query model(s) (there is a very loose coupling between the “write” and “read” model, so it can even happen asynchronously)
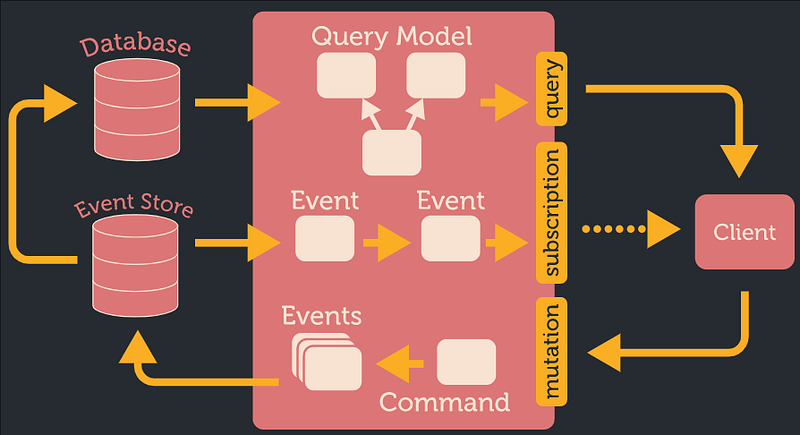
SAGA orchestrator
This approach has a nice compositional property: all subscription field results can be composed together in one data stream. Synchronous iterable sequences can be just concatenated together. Async observable sequences can be merged with operations like merge. So the result of the GraphQL query will be a merged sequence of all subscription field sequences.
Challenges Faced
Centralize data not control
Within a large organisation with multiple APIs, you run the risk of having a monolithic GraphQL server.
Solution
- Each team to maintain its GraphQL schema
- Model exposes a typical CRUD interface
- Wrap in common export
- Aggregate into a central microservice
- API Composition
Developer Experience
Developer fatigue can quickly set in if each developer has to spend time setting up all the connections, interfaces, and pipelines.
Solution
- CLI to create the boilerplate for a GraphQL data source
- Step by step tutorial for building a new data source
- Unit test with coverage
- CI pipeline boilerplate
- Documentation / Tutorials
Improve error handling
Your GraphQL server will be aggregating multiple data sources. Errors can get lost in the shuffle, or even worse return a generic message like “Internal server error”.
Solution
- The source of error must be immediately clear
- A clear description of what went wrong
- Clarity about where the error occurred
- Information that helps trace bugs
- Unique IDs shared on client and server-side
- Support tickets should have this unique ID sent along with details of the error
Schema Versioning
Though a GraphQL service can be versioned like any other API, you need to consider the strengths of GraphQL. Most APIs version due to limited control over data returned and any change can be considered a breaking change. GraphQL only returns data explicitly requested, thus new fields and types can be added without creating a breaking change.
Solution
- Convention over configuration
- Backward compatible changes
- API Evolution
Performance
With GraphQL you can tend to repeatedly load the same data and cause bottlenecks at the DB or service layers.
Solution
- Responses to the client should use JSON and be compressed
- Caching Data at all layers of the architecture
- Rate limiting to protect against denial of service attacks
- Batching multiple requests before forwarding to DB or microservice
- Performance monitoring of resolvers & individual attributes
Security
You will need to consider the security of your GraphQL server and queries in the same way you would with both REST APIs and SQL statements. There are possibilities for infinite recursion, information leaks etc.
Solution
- Validating the schema before and after stitching
- Consistent authorization checks using a dedicated service
- Authorization should not be handled by resolvers at the GraphQL layer
- Do not add “hidden” administrative functionality as GraphQL introspection will easily expose those
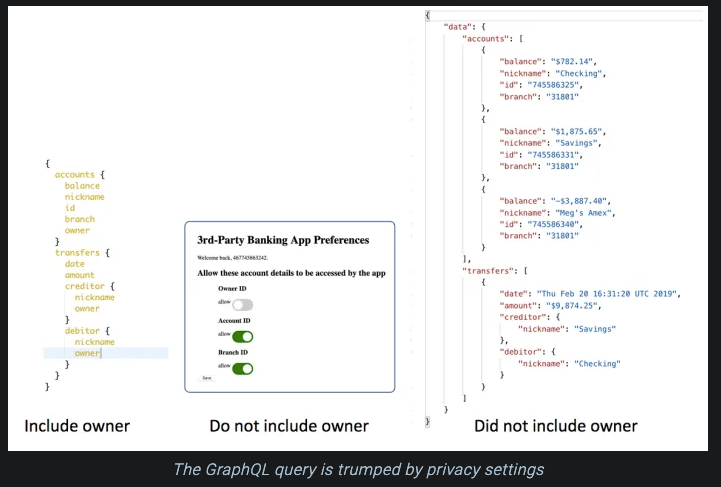
Access Control
You need to consider fine-grained access to each field especially if you are considering the possibility to have an Open API. Along with authorization level access control, you should consider building dynamic access control into your implementation.
Solution
- Resolver access level settings
- Query / Fields access level settings
- A user should be able to override the GraphQL API with their own privacy choices at runtime
Implementation Strategy
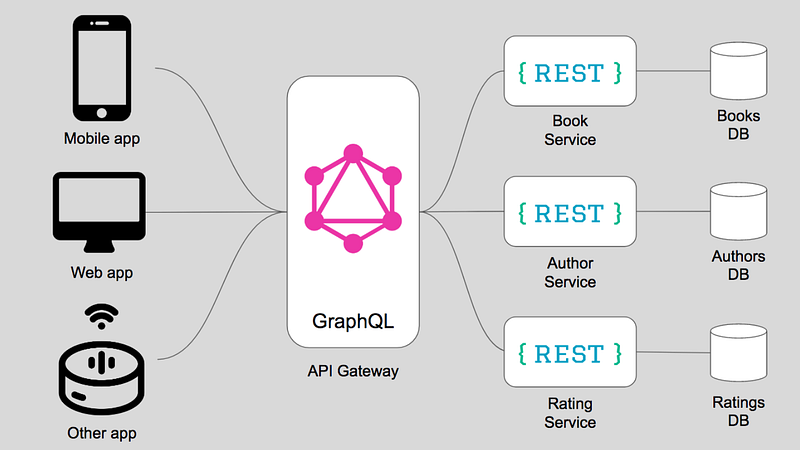
Hybrid Approach
The aim should be to minimise the work that may need to be done by any other teams. Also, create a reference architecture for new GraphQL services/endpoints
This GraphQL server will do nothing more than aggregate data or other graphs from each microservice and just relay data to and fro. Thus the microservices could remain in whatever API format it already is in and the GraphQL server will manipulate the data in the best way possible.
- Use GraphQL as a dumb “API Gateway”
- Using Apollo Federation to stitch together multiple graphs
- Kong handles Authentication / ACL
- GraphQL Server handles routing
- Each GraphQL data source would expose the ACLs needed
- Multi-layer caching in front and behind the GraphQL Server
Possible Tools
- Apollo (Studio, Federation, Client, Server)
- Weaver
- Keystone 5
- TypeGraphQL
- InQL Scanner
- GraphQL Tools
- GraphQL Shield
- GraphQL Doctor
- GrAMPs Middleware
Note: Other tools can be found
- https://graphql.org/code/
- https://github.com/joshblack/awesome-graphql
- https://github.com/chentsulin/awesome-graphql
Conclusion
You can see that GraphQL is extremely good at describing schemas while stitching together different APIs into, yes you guessed it, a Graph!
In a microservices architecture different APIs are exactly what you have. With the use of GraphQL, you can reap the benefits from the microservices architecture while abstracting the complexity to the client.
Using this approach you can ask the server WHAT you want (declarative) exactly rather than take resources and implement it HOW you want (imperative).
GraphQL is often presented as a perfect solution for every problem, but one needs to realize it meets a subset of requirements well, and if these are not part of your requirements, it may not be the best solution for your implementation
The solutions presented here may not be perfect but shows the extensive possibilities and even more important the ability to slowly evolve parts of the system in isolation and expanding on the separation of concerns within the different services.
Highlights
- Querying and aggregating multiple resources at the same time and in a single request
- A query matches the response and thus documentation is not needed to understand the response structure
- Able to query nested resources
- The introduction of GraphQL does not mean dismissal of the REST Architecture but can work in concert with it
- GraphQL is not the only way to make this possible. JSON:API specification gives us something similar in a less elegant package